Introdução
Na minha experiência, desenvolver uma aplicação Spark com código testável não costuma ser tarefa fácil para muitos profissionais de dados. Não pretendo discutir os motivos disso.
Nesta postagem, apresento o que funciona para mim quando preciso desenvolver uma aplicação Spark. Este texto é composto de duas seções. Na primeira, TDD - Desenvolvendo código a partir de testes, mostro um exemplo de como desenvolver um código modular, de fácil leitura e compreensão e, consequentemente, fácil de manter. Na última seção, Mais que produzir um código bonito, é sobre construir conhecimento organizacional, enfatizo os benefícios de usar TDD para desenvolver projetos em dados, suportado tanto pela minha experiência, quanto por publicações de outros blogs e livros.
Este texto não é um tutorial. Mesmo assim, ele pode ajudar profissionais de dados a desenvolver um código melhor. Detalhes de implementação, como preparar o ambiente para desenvolvimento local ou como usar o PyTest, não serão tratados aqui,
TDD - Desenvolvendo código a partir de testes
O problema
Vamos supor que recebemos a tarefa de desenvolver um processo para ler vários arquivos CSV, adequar tanto os nomes das colunas quanto seus tipos. Não temos mais informações como carga de trabalho esperada, intervalo de valores de campos numéricos ou valores esperados para colunas categóricas. O PO, contudo, garante que o nome das colunas será sempre igual a amostra fornecida. Vamos começar.
Pensando sobre a estrutura do repositório e dos arquivos de teste
Uma possível estrutura para o repositório deste projeto é apresentada no diagrama abaixo:
spark-unit-test-example
┣ notebooks
┃ ┗ ...
┣ tests
┃ ┗ ...
┗ README.md
O repositório spark-unit-test-example apresenta duas pastas e um arquivo README.md. Na pasta notebooks, colocaremos os arquivos da aplicação Spark. Na pasta tests, colocaremos os arquivos com os testes das funções que compõem a aplicação.
Quanto à estrutura dos arquivos de teste, podemos começar pelo seguinte:
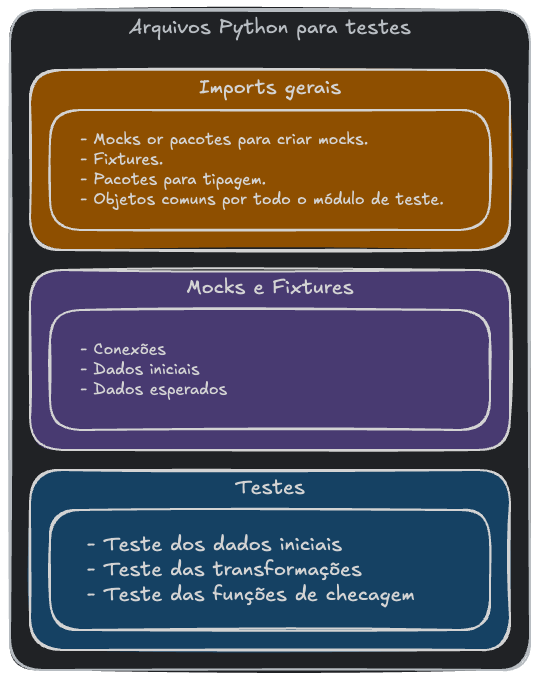
Em código, a estrutura seria algo similar ao apresentado abaixo:
import sys
import pytest
from pyspark.sql import SparkSession
from pyspark_test import assert_pyspark_df_equal
@pytest.fixture(scope="module")
def spark():
...
@pytest.fixture(scope="module")
def mock_base(spark):
...
@pytest.fixture(scope="module")
def mock_expected_change_column_names(spark):
...
@pytest.fixture(scope="module")
def mock_expected_change_column_types(spark):
...
def test_mock_base(mock_base):
assert mock_base.count() > 0
@pytest.mark.skip(reason="TBD")
def test_change_column_names(mock_base, mock_expected_change_column_names):
sys.append('./notebooks')
from ... import change_column_names
...
@pytest.mark.skip(reason="TBD")
def test_change_column_types(mock_base, mock_expected_change_column_types):
sys.append('./notebooks')
from ... import change_column_types
...
O código acima será o conteúdo do arquivo de teste hop_raw2bronze_test.py. É uma ideia inicial que sofrerá alterações. Por hora, temos o seguinte:
-
Imports gerais:
sys: pacote usado para acessar variáveis do Runtime do Python. Em particular, estamos interessados em adicionar o caminho da pastanotebookpara o módulo de busca de caminhos.pytest: cria dados e conexões de forma confiável que podem ser usadas durante a sessão de testes. Também podemos usar decorators para pular alguns testes que ainda não desejamos testar.SparkSession: usado para simular a conexão com um Cluster Spark e mockar os DataFrames.assert_pyspark_df_equal: usado para testar se dois DataFrames Spark são iguais.
-
Mocks e fixtures:
spark: cria a conexão simulada com o cluster Spark.mock_base: mocka o conjunto de dados inicial. Subsitui o resultado doDataFrameReaderquando lemos os arquivos CSV na origem real..mock_expected: cada função com o nomemock_expectedmocka os DataFrames esperados após a execução da respectiva transformação.
-
Testes:
test_mock_base: verifica se o DataFrame inicial criado não é vazio.- other
tests: cada teste avaliará o resultado da sua correspondente função de transformação..
Agora, a estrutura do reposit[orio é a seguinte:
spark-unit-test-example
┣ notebooks
┃ ┗ ...
┣ tests
┃ ┗ hop_raw2bronze_test.py
┗ README.md
Agora podemos começar a desenvolver e implementar os testes.
Implementando as fixtures spark e mock_base
Primeiro, precisamos implementar as fixtures spark e mock_base. A primeira fixture irá simular a SparkSession da aplicação, já a segunda substitui o resultado do processo de leitura dos arquivos CSV . Para verificar que o mock_base inicial foi criado, exibimos o resultado na tela e também criamos um teste simples . O trecho abaixo apresenta a implementação destas fixtures e do teste:
...
@pytest.fixture(scope="module")
def spark():
spark_session = SparkSession.builder \
.appName("Spark Unit Test") \
.getOrCreate()
return spark_session
@pytest.fixture(scope="module")
def mock_base(spark):
mock_data = [
{
"Customer ID": "1",
"Age": "20",
"Gender": "Male",
"Item Purchased": "Blouse",
"Category": "Clothing",
"Purchase Amount (USD)": "53",
"Location": "Montana",
"Size": "L",
"Color":"Blue",
"Season": "Spring",
"Review Rating": "3.1",
"Subscription Status": "Yes",
"Payment Method": "Credit Card",
"Shipping Type": "Free Shipping",
"Discount Applied": "No",
"Promo Code Used": "No",
"Previous Purchases": "5",
"Preferred Payment Method": "Credit Card",
"Frequency of Purchases": "Weekly"
},
]
schema = """
`Customer ID` string,
`Age` string,
`Gender` string,
`Item Purchased` string,
`Category` string,
`Purchase Amount (USD)` string,
`Location` string,
`Size` string,
`Color` string,
`Season` string,
`Review Rating` string,
`Subscription Status` string,
`Payment Method` string,
`Shipping Type` string,
`Discount Applied` string,
`Promo Code Used` string,
`Previous Purchases` string,
`Preferred Payment Method` string,
`Frequency of Purchases` string
"""
df = spark.createDataFrame(mock_data, schema=schema)
df.show()
return df
...
def test_mock_base(mock_base):
assert mock_base.count() == 1
Estamos mockando apenas uma linha no DataFrame base e, caso necessário, incluiremos mais linhas posteriormente. Já que estamos esperando ler arquivos CSV, definimos todos os tipos como String . Feito isso, podemos executar o teste com o Pytest. Após aprovado, teremos uma saída parecida com o que é apresentado abaixo:
...
+-----------+---+------+--------------+--------+---------------------+--------+----+-----+------+-------------+-------------------+--------------+-------------+----------------+---------------+------------------+------------------------+----------------------+
|Customer ID|Age|Gender|Item Purchased|Category|Purchase Amount (USD)|Location|Size|Color|Season|Review Rating|Subscription Status|Payment Method|Shipping Type|Discount Applied|Promo Code Used|Previous Purchases|Preferred Payment Method|Frequency of Purchases|
+-----------+---+------+--------------+--------+---------------------+--------+----+-----+------+-------------+-------------------+--------------+-------------+----------------+---------------+------------------+------------------------+----------------------+
| 1| 20| Male| Blouse|Clothing| 53| Montana| L| Blue|Spring| 3.1| Yes| Credit Card|Free Shipping| No| No| 5| Credit Card| Weekly|
+-----------+---+------+--------------+--------+---------------------+--------+----+-----+------+-------------+-------------------+--------------+-------------+----------------+---------------+------------------+------------------------+----------------------+
PASSED
=============================== warnings summary ===============================
...
Com o teste finalizado, podemos remover o df.show() da fixture mock_base e seguir com o desenvolvimento.
Implementando a função change_column_names
Para implementar a função change_column_names, precisamos da fixture para mockar o resultado esperado da função e o seu teste. Ambos são apresentados abaixo:
@pytest.fixture(scope="module")
def mock_expected_change_column_names(spark):
mock_data = [
{
"customer_id": "1",
"age": "20",
"gender": "Male",
"item_purchased": "Blouse",
"category": "Clothing",
"purchase_amount_usd": "53",
"location": "Montana",
"size": "L",
"color":"Blue",
"season": "Spring",
"review_rating": "3.1",
"subscription_status": "Yes",
"payment_method": "Credit Card",
"shipping_type": "Free Shipping",
"discount_applied": "No",
"promo_code_used": "No",
"previous_purchases": "5",
"preferred_payment_method": "Credit Card",
"frequency_of_purchases": "Weekly"
},
]
schema = """
customer_id string,
age string,
gender string,
item_purchased string,
category string,
purchase_amount_usd string,
location string,
size string,
color string,
season string,
review_rating string,
subscription_status string,
payment_method string,
shipping_type string,
discount_applied string,
promo_code_used string,
previous_purchases string,
preferred_payment_method string,
frequency_of_purchases string
"""
df = spark.createDataFrame(mock_data, schema=schema)
return df
...
def test_change_column_names(mock_base, mock_expected_change_column_names):
sys.path.append('./notebooks')
from hop_raw2bronze import change_column_names
df_transformed = change_column_names(mock_base)
df_transformed.show()
assert_pyspark_df_equal(df_transformed, mock_expected_change_column_names)
Este é o primeiro teste de uma função da aplicação que estamos construindo. No início do teste, adicionamos o caminho da pasta notebook para que o Runtime do Python localize os arquivos da aplicação. Feito isso, o DataFrame df_transformed é criado como resultado da função change_column_names aplicada ao dado mockado mock_base. Por fim, checamos se o resultado df_transformed é igual ao resultado esperado mock_expected_change_column_names.
Agora que o teste foi desenvolvido, podemos implementar a função da aplicação no arquivo hop_raw2bronze.py dentro da pasta notebooks. A atualização da estrutura de arquivos é apresentada abaixo
spark-unit-test-example
┣ notebooks
┃ ┗ hop_raw2bronze.py
┣ tests
┃ ┗ hop_raw2bronze_test.py
┗ README.md
No arquivo hop_raw2bronze.py, podemos escrever qualquer coisa desde que resulte na aprovação do teste test_change_column_names. Existem várias formas de se fazer isso, uma delas é apresentada abaixo:
from pyspark.sql import DataFrame
def change_column_names(df: DataFrame) -> DataFrame:
return df.selectExpr(
"`Customer ID` as customer_id",
"`Age` as age",
"`Gender` as gender",
"`Item Purchased` as item_purchased",
"`Category` as category",
"`Purchase Amount (USD)` as purchase_amount_usd",
"`Location` as location",
"`Size` as size",
"`Color` as color",
"`Season` as season",
"`Review Rating` as review_rating",
"`Subscription Status` as subscription_status",
"`Payment Method` as payment_method",
"`Shipping Type` as shipping_type",
"`Discount Applied` as discount_applied",
"`Promo Code Used` as promo_code_used",
"`Previous Purchases` as previous_purchases",
"`Preferred Payment Method` as preferred_payment_method",
"`Frequency of Purchases` as frequency_of_purchases"
)
Na próxima etapa, executamos o Pytest para ver se a nossa implementação é aprovada. No cotidiano, iríamos alterar o código da função da aplicação até ela ser aprovada no teste. O resultado do teste aprovado seria algo parecido com trecho exibido abaixo:
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
...
PASSED
spark-unit-test-example/tests/hop_raw2bronze_test.py::test_change_column_names +-----------+---+------+--------------+--------+-------------------+--------+----+-----+------+-------------+-------------------+--------------+-------------+----------------+---------------+------------------+------------------------+----------------------+
|customer_id|age|gender|item_purchased|category|purchase_amount_usd|location|size|color|season|review_rating|subscription_status|payment_method|shipping_type|discount_applied|promo_code_used|previous_purchases|preferred_payment_method|frequency_of_purchases|
+-----------+---+------+--------------+--------+-------------------+--------+----+-----+------+-------------+-------------------+--------------+-------------+----------------+---------------+------------------+------------------------+----------------------+
| 1| 20| Male| Blouse|Clothing| 53| Montana| L| Blue|Spring| 3.1| Yes| Credit Card|Free Shipping| No| No| 5| Credit Card| Weekly|
+-----------+---+------+--------------+--------+-------------------+--------+----+-----+------+-------------+-------------------+--------------+-------------+----------------+---------------+------------------+------------------------+----------------------+
PASSED
...```
Agora, podemos remover o df_transformed.show() no teste e seguir para a próxima função.
Implementando a função change_column_types
De forma similar, ao que fizemos na seção anterior, começamos desenvolvendo as fixtures para mockar os dados esperados e a função de teste. Mas, agora, precisamos de melhores definições para construir uma aplicação que não comprometa a qualidade dos dados e que tire melhor proveito dos recursos durante o processamento.
O tipo para o campo age, por se tratar de idade humana, podemos inferir como tipo tinyint, uma vez que este tipo de valor usa apenas 1 byte e pode representar os números de -128 à 127. Caso mantivéssemos como tipo String, considerando que a maioria das pessoas possuem idade de dois dígitos, o valor para este campo em uma linha poderia ser de 42 bytes dada a seguinte fórmula:
byte_size = 2 * (num_of_characteres) + 38
Com exceção dos campos restantes cujos valores são texto, não podemos escolher a tipagem sem ter uma melhor definição da área de negócios. Além do problema de otimização do uso de memória, a qualidade dos dados pode ser comprometida. Problemas de encode podem acontecer nos campos numéricos customer_id, purchase_amount_usd e review_rating e, se não formos cuidadosos, podemos propagar este problema para demais processos que consomem os dados da tabela que estamos criando. Além disso, também não teríamos como informar sobre este problema aos responsáveis e melhorar o pipeline como um todo.
É comum alinharmos que os tipos de dado serão iguais aos do sistema de origem, mas isso poderia não ser possível para o campo purchase_amount_usd . Em sistemas transacionais, onde geralmente não ocorrem operações de agregação, este campo poderia ser de algum tipo ponto flutuante. Contudo, em sistemas analíticos, onde é comum que agregações aconteçam, isso poderia ser problemático. Tipos numéricos de ponto flutuante não tem precisão fixa e, por isso, o valor da soma deste campo em uma tabela com milhões de linhas de linhas poderia resultar em valores aleatórios devido à aritmética dos pontos flutuantes. Então, devemos definir algum tipo de dado de precisão fixa, bem como qual a precisão adotar.
Para prosseguir com o texto, vamos supor que o alinhamento foi devidademente realizado e que chegamos no seguinte resultado:
...
@pytest.fixture(scope="module")
def mock_expected_change_column_types(spark):
from decimal import Decimal
mock_data = [
{
"customer_id": 1,
"age": 20,
"gender": "Male",
"item_purchased": "Blouse",
"category": "Clothing",
"purchase_amount_usd": Decimal(53.0),
"location": "Montana",
"size": "L",
"color":"Blue",
"season": "Spring",
"review_rating": 3.1,
"subscription_status": "Yes",
"payment_method": "Credit Card",
"shipping_type": "Free Shipping",
"discount_applied": "No",
"promo_code_used": "No",
"previous_purchases": 5,
"preferred_payment_method": "Credit Card",
"frequency_of_purchases": "Weekly"
},
]
schema = """
customer_id bigint,
age tinyint,
gender string,
item_purchased string,
category string,
purchase_amount_usd decimal(10,5),
location string,
size string,
color string,
season string,
review_rating double,
subscription_status string,
payment_method string,
shipping_type string,
discount_applied string,
promo_code_used string,
previous_purchases int,
preferred_payment_method string,
frequency_of_purchases string
"""
df = spark.createDataFrame(mock_data, schema=schema)
return df
...
def test_change_column_types(mock_base, mock_expected_change_column_types):
sys.path.append('app/spark-unit-test-example/notebooks')
from hop_raw2bronze import change_column_names, change_column_types
df_names = change_column_names(mock_base)
df_transformed = change_column_types(df_names)
assert_pyspark_df_equal(df_transformed, mock_expected_change_column_types)
Agora, podemos implementar a função change_column_types no módulo hop_raw2bronze. Uma das possibilidades é apresentada abaixo:
...
def change_column_types(df: DataFrame) -> DataFrame:
return df.selectExpr(
"cast(customer_id as bigint) customer_id",
"cast(age as tinyint) age",
"cast(gender as string) gender",
"cast(item_purchased as string) item_purchased",
"cast(category as string) category",
"cast(purchase_amount_usd as decimal(10,5)) purchase_amount_usd",
"cast(location as string) location",
"cast(size as string) size",
"cast(color as string) color",
"cast(season as string) season",
"cast(review_rating as double) review_rating",
"cast(subscription_status as string) subscription_status",
"cast(payment_method as string) payment_method",
"cast(shipping_type as string) shipping_type",
"cast(discount_applied as string) discount_applied",
"cast(promo_code_used as string) promo_code_used",
"cast(previous_purchases as int) previous_purchases",
"cast(preferred_payment_method as string) preferred_payment_method",
"cast(frequency_of_purchases as string) frequency_of_purchases",
)
...
Agora, executamos o teste usando o Pytest. Algo similar ao trecho abaixo será exibido caso os testes sejam aprovados.
============================= test session starts ==============================
...
app/spark-unit-test-example/tests/hop_raw2bronze_test.py::test_mock_base ps: unrecognized option: p
...
PASSED [ 33%]
app/spark-unit-test-example/tests/hop_raw2bronze_test.py::test_change_column_names PASSED [ 66%]
app/spark-unit-test-example/tests/hop_raw2bronze_test.py::test_change_column_types PASSED [100%]
Implementando a função check_constraints
Para implementar a função check_contraints que verifica a qualidade dos dados que processamos, precisamos definir as regras de qualidade de dados, construir os mocks e o teste. Também precisamos definir quais caminhos adotar nos casos em que as regras são violadas. Aqui estão algumas das possibilidades:
- Quando há uma violação, o valor é removido do DataFrame e, então, prosseguimos com a execução da aplicação. Os times de engenharia e o de negócios concordaram que o possível volume de dados inadequados não é considerável e pode ser descartado.
- Quando há uma violação, interrompemos a aplicação e levantamos uma exceção que exibe o número total de casos de violação, bem como exibimos uma pequena amostra destes dados. Os times de engenharia e de negócios concordaram que, em casos de violação, devemos interromper o processo e prover informações suficientes ao time responsável para identificar a causa raiz destes problemas.
- Quando há uma violação, levantamos um alerta e prosseguimos com a execução da aplicação. Os times de engenharia e o de negócios concordaram que é esperada uma certa quantidade de dados de má qualidade na tabela bronze, e que temos outras ferramentas monitorando a qualidade dos dados nesta tabela. Usare esta ferramenta para bloquear a gravação dos dados na tabela caso as métricas de qualidade atinjam um determinado valor.
Qualquer decisão tomada deve ser alinhada com o time de negócios. Aqui, vamos prosseguir com a segunda opção e considerar as seguintes regras:
- O campo
customer_idnão pode ter valor nulo. - Os campos
review_ratingeprevious_purchasesnão podem apresentar valores nulos ou negativos.
Devemos testar o comportamento da função tanto no cenário onde não há dados que violam as regras, quanto no cenário que violam as regras. Para isso, mockamos um DataFrame que possui uma linha que viola cada uma das 5 regras. A fixture para o mock é apresentada abaixo:
@pytest.fixture(scope="module")
def mock_check_constraints_fail(spark):
from decimal import Decimal
mock_data = [
{
# customer_id is Null
"customer_id": None,
"age": 20,
"gender": "Male",
"item_purchased": "Blouse",
"category": "Clothing",
"purchase_amount_usd": Decimal(53.0),
"location": "Montana",
"size": "L",
"color":"Blue",
"season": "Spring",
"review_rating": 3.1,
"subscription_status": "Yes",
"payment_method": "Credit Card",
"shipping_type": "Free Shipping",
"discount_applied": "No",
"promo_code_used": "No",
"previous_purchases": 5,
"preferred_payment_method": "Credit Card",
"frequency_of_purchases": "Weekly"
},
{
# review_rating is Negative
"customer_id": 1,
"age": 20,
"gender": "Male",
"item_purchased": "Blouse",
"category": "Clothing",
"purchase_amount_usd": Decimal(53.0),
"location": "Montana",
"size": "L",
"color":"Blue",
"season": "Spring",
"review_rating": -0.1,
"subscription_status": "Yes",
"payment_method": "Credit Card",
"shipping_type": "Free Shipping",
"discount_applied": "No",
"promo_code_used": "No",
"previous_purchases": 5,
"preferred_payment_method": "Credit Card",
"frequency_of_purchases": "Weekly"
},
{
# review_rating is Null
"customer_id": 1,
"age": 20,
"gender": "Male",
"item_purchased": "Blouse",
"category": "Clothing",
"purchase_amount_usd": Decimal(53.0),
"location": "Montana",
"size": "L",
"color":"Blue",
"season": "Spring",
"review_rating": None,
"subscription_status": "Yes",
"payment_method": "Credit Card",
"shipping_type": "Free Shipping",
"discount_applied": "No",
"promo_code_used": "No",
"previous_purchases": 5,
"preferred_payment_method": "Credit Card",
"frequency_of_purchases": "Weekly"
},
{
# previous_purchases is Negative
"customer_id": 1,
"age": 20,
"gender": "Male",
"item_purchased": "Blouse",
"category": "Clothing",
"purchase_amount_usd": Decimal(53.0),
"location": "Montana",
"size": "L",
"color":"Blue",
"season": "Spring",
"review_rating": 3.1,
"subscription_status": "Yes",
"payment_method": "Credit Card",
"shipping_type": "Free Shipping",
"discount_applied": "No",
"promo_code_used": "No",
"previous_purchases": -5,
"preferred_payment_method": "Credit Card",
"frequency_of_purchases": "Weekly"
},
{
# previous_purchases is Null
"customer_id": 1,
"age": 20,
"gender": "Male",
"item_purchased": "Blouse",
"category": "Clothing",
"purchase_amount_usd": Decimal(53.0),
"location": "Montana",
"size": "L",
"color":"Blue",
"season": "Spring",
"review_rating": 3.1,
"subscription_status": "Yes",
"payment_method": "Credit Card",
"shipping_type": "Free Shipping",
"discount_applied": "No",
"promo_code_used": "No",
"previous_purchases": None,
"preferred_payment_method": "Credit Card",
"frequency_of_purchases": "Weekly"
},
]
schema = """
customer_id bigint,
age int,
gender string,
item_purchased string,
category string,
purchase_amount_usd decimal(10,5),
location string,
size string,
color string,
season string,
review_rating double,
subscription_status string,
payment_method string,
shipping_type string,
discount_applied string,
promo_code_used string,
previous_purchases int,
preferred_payment_method string,
frequency_of_purchases string
"""
df = spark.createDataFrame(mock_data, schema=schema)
return df
Seguindo com os testes para ambos os cenários, temos o seguinte:
...
def test_check_contraints_ok(mock_expected_change_column_types):
sys.path.append('./notebooks')
from hop_raw2bronze import check_constraints
check_ok = check_constraints(mock_expected_change_column_types)
assert check_ok
def test_check_constraints_fail(mock_check_constraints_fail):
sys.path.append('./notebooks')
from hop_raw2bronze import check_constraints
with pytest.raises(ValueError) as info:
check_constraints(mock_check_constraints_fail)
bad_rows = info.value.args[1]
assert bad_rows == 5
...
O primeirio teste apresentado acima verifica o cenário em que não há violação das regras. Por hora, o mock mock_expected_change_column_types nos serve para esta função e, caso necessário, podemos criar um novo mock ou adicionar novos dados para contemplar novos cenários, documentando as novas regras no código. No segundo teste, capturamos a mensagem fornecida pela exceção ValueError da função da aplicação. O segundo argumento desta exceção nos fornecerá o número total de linhas que violam as regras definidas.
Em seguida, podemos desenvolver a função no módulo hop_raw2bronze. Uma das possibilidades de implementação é apresentada abaixo:
...
def check_constraints(df: DataFrame) -> DataFrame:
df_check = df.filter(
"""
(customer_id is null)
or (review_rating < 0)
or (review_rating is null)
or (previous_purchases < 0)
or (previous_purchases is null)
"""
)
check = df_check.isEmpty()
if check:
return True
df_string = df.limit(10).toPandas().to_string()
df_count = df.count()
error_msg = f"""
[VALUE ERROR] Constraints were violated.
- customer_id must not be null.
- review_rating must be equal or greater than zero.
- previous_purchases must be equal or greater than zero.
Showing up to 10 rows that violates the rules above:
{df_string}
"""
print(df_string)
raise ValueError("Total Lines:", df_count, error_msg)
...
Executando o teste no Pytest, obteremos algo similar ao que é apresentado abaixo
============================= test session starts ==============================
...
app/spark-unit-test-example/tests/hop_raw2bronze_test.py::test_change_column_names ps: unrecognized option: p
...
WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
PASSED [ 25%]
app/spark-unit-test-example/tests/hop_raw2bronze_test.py::test_change_column_types PASSED [ 50%]
app/spark-unit-test-example/tests/hop_raw2bronze_test.py::test_check_contraints_ok PASSED [ 75%]
app/spark-unit-test-example/tests/hop_raw2bronze_test.py::test_check_constraints_fail customer_id age gender item_purchased category purchase_amount_usd location size color season review_rating subscription_status payment_method shipping_type discount_applied promo_code_used previous_purchases preferred_payment_method frequency_of_purchases
0 NaN 20 Male Blouse Clothing 53.00000 Montana L Blue Spring 3.1 Yes Credit Card Free Shipping No No 5.0 Credit Card Weekly
1 1.0 20 Male Blouse Clothing 53.00000 Montana L Blue Spring -0.1 Yes Credit Card Free Shipping No No 5.0 Credit Card Weekly
2 1.0 20 Male Blouse Clothing 53.00000 Montana L Blue Spring NaN Yes Credit Card Free Shipping No No 5.0 Credit Card Weekly
3 1.0 20 Male Blouse Clothing 53.00000 Montana L Blue Spring 3.1 Yes Credit Card Free Shipping No No -5.0 Credit Card Weekly
4 1.0 20 Male Blouse Clothing 53.00000 Montana L Blue Spring 3.1 Yes Credit Card Free Shipping No No NaN Credit Card Weekly
PASSED [100%]
=============================== warnings summary ===============================
...
======================== 4 passed, 2 warnings in 20.56s ========================
Ainda podemos escrever uma função que execute as transformações na ordem que precisamos.
Implementando a função transformations
É esperado que a função transformations faça i seguinte:
- Receba o DataFrame “bruto” da leitura dos arquivos.
- Cria o DataFrame
df_change_namescomo resultado da funçãochange_column_namesa partir do DataFrame bruto. - Cria o DataFrame
df_resultcomo resultado da funçãochange_column_typesa partir dodf_change_names. - Feito isso, checamos a qualidade dos dados do
df_resultde acordo com as regras da funçãocheck_constraints. - Caso a função
check_constraintsretornar verdadeiro, retornamos odf_resultpara escrever na tabela bronze.
Da mesma forma, temos um caminho feliz e um com tratamento de exceção. Para o caminho feliz, podemos usar a fixture mock_base. Para o caminho com exceção, criaremos a fixture mock_base_fail, que é apresentada abaixo.
@pytest.fixture(scope="module")
def mock_base_fail(spark):
mock_data = [
{
"Customer ID": "1",
"Age": "20",
"Gender": "Male",
"Item Purchased": "Blouse",
"Category": "Clothing",
"Purchase Amount (USD)": "53",
"Location": "Montana",
"Size": "L",
"Color":"Blue",
"Season": "Spring",
"Review Rating": "-3.1",
"Subscription Status": "Yes",
"Payment Method": "Credit Card",
"Shipping Type": "Free Shipping",
"Discount Applied": "No",
"Promo Code Used": "No",
"Previous Purchases": "5",
"Preferred Payment Method": "Credit Card",
"Frequency of Purchases": "Weekly"
},
]
schema = """
`Customer ID` string,
`Age` string,
`Gender` string,
`Item Purchased` string,
`Category` string,
`Purchase Amount (USD)` string,
`Location` string,
`Size` string,
`Color` string,
`Season` string,
`Review Rating` string,
`Subscription Status` string,
`Payment Method` string,
`Shipping Type` string,
`Discount Applied` string,
`Promo Code Used` string,
`Previous Purchases` string,
`Preferred Payment Method` string,
`Frequency of Purchases` string
"""
df = spark.createDataFrame(mock_data, schema=schema)
return df
Em seguida, podemos criar os testes da criação do mock acima e para checar o comportamento da função transformations.
...
def test_mock_base_fail(mock_base_fail):
assert mock_base_fail.count() == 1
def test_transformations_ok(mock_base, mock_expected_change_column_types):
sys.path.append('./notebooks')
from hop_raw2bronze import transformations
df_transformed = transformations(mock_base)
assert_pyspark_df_equal(df_transformed, mock_expected_change_column_types)
def test_transformations_fail(mock_base_fail):
sys.path.append('./notebooks')
from hop_raw2bronze import transformations
with pytest.raises(ValueError) as info:
transformations(mock_base_fail)
bad_rows = info.value.args[1]
assert bad_rows == 1
Abaixo, temos uma possíivel implementação da função transformations no módulo hop_raw2bronze:
...
def transformations(df: DataFrame) -> DataFrame:
df_change_names = change_column_names(df)
df_result= change_column_types(df_change_names)
check = check_constraints(df_result)
if check:
return df_result
...
Executando o Pytest com sucesso, obteremos um resuttado parecido com o que é apresentado abaixo:
============================= test session starts ==============================
...
WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
PASSED [ 14%]
app/spark-unit-test-example/tests/hop_raw2bronze_test.py::test_change_column_names PASSED [ 28%]
app/spark-unit-test-example/tests/hop_raw2bronze_test.py::test_change_column_types PASSED [ 42%]
app/spark-unit-test-example/tests/hop_raw2bronze_test.py::test_check_contraints_ok PASSED [ 57%]
app/spark-unit-test-example/tests/hop_raw2bronze_test.py::test_check_constraints_fail customer_id age gender item_purchased category purchase_amount_usd location size color season review_rating subscription_status payment_method shipping_type discount_applied promo_code_used previous_purchases preferred_payment_method frequency_of_purchases
0 NaN 20 Male Blouse Clothing 53.00000 Montana L Blue Spring 3.1 Yes Credit Card Free Shipping No No 5.0 Credit Card Weekly
1 1.0 20 Male Blouse Clothing 53.00000 Montana L Blue Spring -0.1 Yes Credit Card Free Shipping No No 5.0 Credit Card Weekly
2 1.0 20 Male Blouse Clothing 53.00000 Montana L Blue Spring NaN Yes Credit Card Free Shipping No No 5.0 Credit Card Weekly
3 1.0 20 Male Blouse Clothing 53.00000 Montana L Blue Spring 3.1 Yes Credit Card Free Shipping No No -5.0 Credit Card Weekly
4 1.0 20 Male Blouse Clothing 53.00000 Montana L Blue Spring 3.1 Yes Credit Card Free Shipping No No NaN Credit Card Weekly
PASSED [ 71%]
app/spark-unit-test-example/tests/hop_raw2bronze_test.py::test_transformations_ok PASSED [ 85%]
app/spark-unit-test-example/tests/hop_raw2bronze_test.py::test_transformations_fail customer_id age gender item_purchased category purchase_amount_usd location size color season review_rating subscription_status payment_method shipping_type discount_applied promo_code_used previous_purchases preferred_payment_method frequency_of_purchases
0 1 20 Male Blouse Clothing 53.00000 Montana L Blue Spring -3.1 Yes Credit Card Free Shipping No No 5 Credit Card Weekly
PASSED [100%]
=============================== warnings summary ===============================
...
======================== 7 passed, 4 warnings in 22.43s ========================
O módulo hop_raw2bronze finalizado
Abaixo, apresentamos uma sugestão de implementação do módulo hop_raw2bronze:
from pyspark.sql import DataFrame
APP_NAME = "[BATCH] RAW2BRONZE - customer_shopping"
def change_column_names(df: DataFrame) -> DataFrame:
return df.selectExpr(
"`Customer ID` as customer_id",
"`Age` as age",
"`Gender` as gender",
"`Item Purchased` as item_purchased",
"`Category` as category",
"`Purchase Amount (USD)`as purchase_amount_usd",
"`Location` as location",
"`Size` as size",
"`Color` as color",
"`Season` as season",
"`Review Rating` as review_rating",
"`Subscription Status` as subscription_status",
"`Payment Method` as payment_method",
"`Shipping Type` as shipping_type",
"`Discount Applied` as discount_applied",
"`Promo Code Used` as promo_code_used",
"`Previous Purchases` as previous_purchases",
"`Preferred Payment Method` as preferred_payment_method",
"`Frequency of Purchases` as frequency_of_purchases"
)
def change_column_types(df: DataFrame) -> DataFrame:
return df.selectExpr(
"cast(customer_id as bigint) customer_id",
"cast(age as int) age",
"cast(gender as string) gender",
"cast(item_purchased as string) item_purchased",
"cast(category as string) category",
"cast(purchase_amount_usd as decimal(10,5)) purchase_amount_usd",
"cast(location as string) location",
"cast(size as string) size",
"cast(color as string) color",
"cast(season as string) season",
"cast(review_rating as double) review_rating",
"cast(subscription_status as string) subscription_status",
"cast(payment_method as string) payment_method",
"cast(shipping_type as string) shipping_type",
"cast(discount_applied as string) discount_applied",
"cast(promo_code_used as string) promo_code_used",
"cast(previous_purchases as int) previous_purchases",
"cast(preferred_payment_method as string) preferred_payment_method",
"cast(frequency_of_purchases as string) frequency_of_purchases",
)
def check_constraints(df: DataFrame) -> DataFrame:
df_check = df.filter(
"""
(customer_id is null)
or (review_rating < 0)
or (review_rating is null)
or (previous_purchases < 0)
or (previous_purchases is null)
"""
)
check = df_check.isEmpty()
if check:
return True
df_string = df.limit(10).toPandas().to_string()
df_count = df.count()
error_msg = f"""
[VALUE ERROR] Constraints were violated.
- customer_id must not be null.
- review_rating must be equal or greater than zero.
- previous_purchases must be equal or greater than zero.
Showing up to 10 rows that violates the rules above:
{df_string}
"""
print(df_string)
raise ValueError("Total Lines:", df_count, error_msg)
def transformations(df: DataFrame) -> DataFrame:
df_change_names = change_column_names(df)
df_result= change_column_types(df_change_names)
check = check_constraints(df_result)
if check:
return df_result
def main():
spark = ...
df_raw = spark.read.csv('/path/to/csv/files')
df_final = transformations(df_raw)
if check_constraints(df_final):
spark.sparkContext.setJobGroup(APP_NAME, "Hop Raw to Bronze")
df_final.mode("append").saveAsTable("bronze.customer_shopping")
if __name__ == "__main__":
main()
Note que o código acima possui uma estrutura bem definida. A função main injeta df_raw nas funções de mais baixo nível. Caso, algum dia, precisarmos aumentar o número de funções para esta aplicação, podemos concentrar todas as funções em um novo módulo e facilmente refatorar os testes. Por exemplo, podemos criar um módulo hop_raw2bronze_utils com todas as transformações e deixar apenas a lógica da aplicação no módulo hop_raw2bronze. Esta alteração levaria a algo smilar ao que apresentamos abaixo:
from pyspark.sql import DataFrame
from hop_raw2bronze_utils import transformations, checks
APP_NAME = "[BATCH] RAW2BRONZE - customer_shopping"
def main():
spark = ...
df_raw = spark.read.csv('/path/to/csv/files')
df_final = transformations(df_raw)
if check_constraints(df_final):
spark.sparkContext.setJobGroup(APP_NAME, "Hop Raw to Bronze")
df_final.mode("append").saveAsTable("bronze.customer_shopping")
if __name__ == "__main__":
main()
Para alterar os testes, apenas importaríasmos as funções do módulo hop_raw2bronze_utils ao invés do módulo hop_raw2bronze. Mas ainda não falamos tanto ainda do que é, pra mim, a maior vantagem deste método, que é embarcar o conhecimento do negócio
Mais que produzir um código bonito, é sobre construir conhecimento organizacional
No exemplo deste texto, vimos como produzir um código fácil de ler e de manter. Além dos benefícios técnicos, na minha opinião, os principais benefícios do TDD são:
- Exige que a pessoa desenvolvedora pense sobre os requisitos de negócio. Não é incomum recebermos de pessoas de negócios requisitos mal definidos e, se não fizermos a nossa parte para os requisitos venham de forma adequada, acabaremos em cenários onde o retrabalho vira rotina. A metodologia nos ajuda a pensar melhor nas perguntas que podemos fazer ao time de negócios a fim de obter melhores respostas e melhores definições. Isso é bom para o negócio, que pode entregar um produto melhor e de forma mais rápida. Para o desenvolvedor, isso pode significar menos horas extras apagando incêndios.
- Mescla o processo de documentação com o processo de desenvolvimento. É comum iniciarmos o desenvolvimento de código e postergarmos a criação da documentação, ou sequer a criamos. Quando desenvolvemos a partir dos testes, estamos também documentando os requisitos, comportamentos esperados da aplicação, e até mesmo como são os dados que esperamos receber. Em uma perspectiva gerencial, isso significa que novos desenvolvedores levarão menos tempo para entender o contexto do projeto e iniciar as suas atividades.
Muitas empresas e profissionais falam sobre a importância dos testes unitários e do TDD tanto na perspectiva de negócios, quanto na perspectiva técnica. Aqui trago alguns exemplos:
- A Microsoft cita que a implementação de testes unitários melhora tanto a qualidade dos processos, quanto dos produtos destes processos.
- Harsh Patel, Aditi Rajnish, and Raj Pathak mencionam no AWS Machine Learning Blog que "…TDD facilita a colaboração e o compartilhamento de conhecimento entre times, por que testes funcionam como uma documentação viva do conhecimento sobre os comportamentos esperados e as restrições."
- Google também possui publicações que enaltecem o uso de TDD para a produção de um código melhor.
Além de livros como Test Driven Development: By Example e o The DevOps Handbook.
Na minha opinião, aplicar TDD no desenvolvimento de aplicações Spark é favorável a todos. Contribui para o negócio entregar melhores produtos e de forma mais rápida, bem como ajuda na produção de código de fácil entendimento e manutenção. Isso ajuda tanto ter resultados financeiros mais rápido, quanto diminui a possibilidade de cenários onde engenheiros e engenheiras de dados atuam apagando incêndios.
Referências
- Testing PySparkGetting Started with Distroless Images
- About Fixtures
DataFrameReader- How to invoke Pytest
- Exploring Java String Byte Size: Understanding Memory Usage
- Floating Point
- Shift testing left with Unit Tests
- Automate building guardrails for Amazon Bedrock using test-driven development
- Continuous Integration
- Intro to Test Driven Development and How It Benefits Your Business
- Test Driven Development: By Example
- The DevOps Handbook: How to Create World-Class Agility, Reliability, & Security in Technology Organizations